產(chǎn)品介紹
隨著科技的發(fā)展和網(wǎng)絡(luò)的普及�����,人們可獲得的數(shù)據(jù)量越來(lái)越多�����,這些數(shù)據(jù)多數(shù)是以文本形式存在的���。而這些文本數(shù)據(jù)大多是比較繁雜的,這就導(dǎo)致了數(shù)據(jù)量大但信息卻比較匱乏的狀況�。如何從這些繁雜的文本數(shù)據(jù)中獲得有用的信息越來(lái)越受到人們的關(guān)注���?���!霸谖谋疚臋n中發(fā)現(xiàn)有意義或有用的模式的過(guò)程"的文本挖掘技術(shù)為解決這一問(wèn)題提供了一個(gè)有效的途徑��。
知識(shí)發(fā)現(xiàn)與數(shù)據(jù)挖掘是人工智能���、機(jī)器學(xué)習(xí)和數(shù)據(jù)庫(kù)相結(jié)合的產(chǎn)物�。隨著科學(xué)數(shù)據(jù)的大量積累和各種數(shù)據(jù)庫(kù)的廣泛使用�����,人們又逐步認(rèn)識(shí)到海量數(shù)據(jù)的利用十分困難����、效率低下�����,而且很難從中獲得有價(jià)值的指導(dǎo)性意見(jiàn)。在這種情況下�����,數(shù)據(jù)挖掘技術(shù)應(yīng)運(yùn)而生���。
文本挖掘作為數(shù)據(jù)挖掘的一個(gè)新主題?引起了人們的很大興趣�,同時(shí)它也是一個(gè)富于爭(zhēng)議的研究方向����。文本挖掘不但要處理大量的結(jié)構(gòu)化和非結(jié)構(gòu)化的文檔數(shù)據(jù),而且還要處理其中復(fù)雜的語(yǔ)義關(guān)系����,因此���,現(xiàn)有的數(shù)據(jù)挖掘技術(shù)無(wú)法直接應(yīng)用于其上。對(duì)于非結(jié)構(gòu)化問(wèn)題�,一條途徑是發(fā)展全新的數(shù)據(jù)挖掘算法直接對(duì)非結(jié)構(gòu)化數(shù)據(jù)進(jìn)行挖掘��,對(duì)于數(shù)據(jù)非常復(fù)雜����,導(dǎo)致這種算法的復(fù)雜性很高;另一條途徑就是將非結(jié)構(gòu)化問(wèn)題結(jié)構(gòu)化����,利用現(xiàn)有的數(shù)據(jù)挖掘技術(shù)進(jìn)行挖掘���,目前的文本挖掘一般采用該途徑進(jìn)行�。對(duì)于語(yǔ)義關(guān)系����,則需要集成計(jì)算語(yǔ)言學(xué)和自然語(yǔ)言處理等成果進(jìn)行分析。
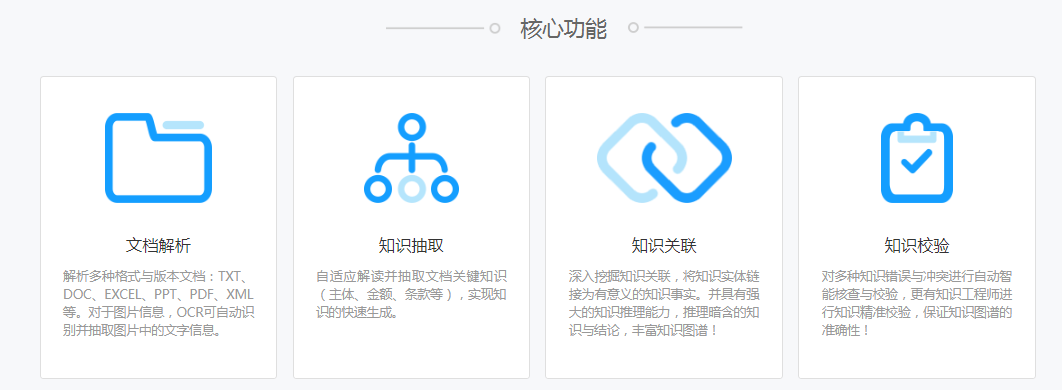
NLPIR大數(shù)據(jù)語(yǔ)義智能分析平臺(tái)平臺(tái)針對(duì)互聯(lián)網(wǎng)內(nèi)容處理的全技術(shù)鏈條的共享開(kāi)發(fā)平臺(tái)。15年專(zhuān)業(yè)研究與工程積累����,提供應(yīng)用軟件及各平臺(tái)下的二次開(kāi)發(fā)包。提供了用于技術(shù)二次開(kāi)發(fā)的基礎(chǔ)工具集。開(kāi)發(fā)平臺(tái)由多個(gè)中間件組成��,各個(gè)中間件API可以無(wú)縫地融合到客戶(hù)的各類(lèi)復(fù)雜應(yīng)用系統(tǒng)之中����。
NLPIR能夠 多角度滿(mǎn)足應(yīng)用者對(duì)大數(shù)據(jù)文本的處理需求,包括大數(shù)據(jù)完整的技術(shù)鏈條:網(wǎng)絡(luò)采集�����、正文提取�、中英文分詞��、詞性標(biāo)注�����、實(shí)體抽取�、詞頻統(tǒng)計(jì)�、關(guān)鍵詞提取、語(yǔ)義信息抽取、文本分類(lèi)、情感分析��、語(yǔ)義深度擴(kuò)展���、繁簡(jiǎn)編碼轉(zhuǎn)換�����、自動(dòng)注音����、文本聚類(lèi)等。
中文數(shù)據(jù)挖掘技術(shù)應(yīng)時(shí)代的要求應(yīng)運(yùn)而生��,在很大程度上滿(mǎn)足了人們對(duì)自然語(yǔ)言處理的需要,解決了人和計(jì)算機(jī)交流中的一些障礙;但中文數(shù)據(jù)挖掘技術(shù)也存在很多困難�����,NLPIR大數(shù)據(jù)語(yǔ)義智能技術(shù)將對(duì)中文數(shù)據(jù)挖掘技術(shù)進(jìn)行深入研究,必將提供出高質(zhì)量�����、多功能的中文數(shù)據(jù)挖掘算法并促進(jìn)自然語(yǔ)言理解系統(tǒng)的廣泛應(yīng)用�。